

摘要:,,本文介绍了分度头应用及其在Linux环境下的数据整合设计方案实践。文章重点阐述了分度头应用的工作原理及其在高速方案规划中的作用。详细描述了刻版25.59.82的具体实施步骤和注意事项。该设计方案旨在提高系统性能,优化数据处理流程,为相关领域提供高效的解决方案。
本文目录导读:
本文将探讨分度头应用在数据处理领域的实际应用,并针对数据整合设计方案进行深入探讨,在Linux环境下,我们将结合具体的技术细节和实现方法,阐述分度头应用的重要性以及数据整合设计方案的实施策略,本文旨在为相关领域的专业人士和爱好者提供有价值的参考信息。
分度头应用概述
分度头是一种常用于数据处理领域的工具,主要用于将大型数据集分割成较小的片段,以便于处理和分析,在Linux环境下,分度头应用可以广泛应用于各种数据处理场景,如大数据分析、机器学习、云计算等,通过对数据的分割和处理,分度头应用能够提高数据处理效率,降低系统负载,从而更好地满足实际需求。
数据整合设计方案
数据整合是数据处理过程中至关重要的一环,它涉及到将不同来源、格式和结构的数据进行统一整合和处理,以便于后续的分析和应用,在数据整合设计方案中,我们需要考虑以下几个方面:
1、数据源整合:将不同来源的数据进行统一管理和整合,包括结构化数据、半结构化数据和非结构化数据。
2、数据清洗:对收集到的数据进行清洗和预处理,去除无效和冗余数据,提高数据质量。
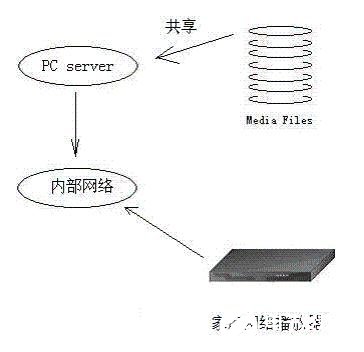
3、数据存储:选择合适的数据存储方案,确保数据的可靠性、安全性和高效性。
4、数据访问控制:对数据进行访问控制和权限管理,确保数据的安全性和隐私性。
在Linux环境下,我们可以利用各种开源工具和框架来实现数据整合设计方案,可以使用Hadoop、Spark等大数据处理框架来处理和分析大规模数据集;使用Elasticsearch、Solr等搜索引擎技术来实现高效的数据检索和查询;使用NoSQL数据库来存储和管理非结构化数据等。
三、Linux环境下的分度头应用与数据整合实践
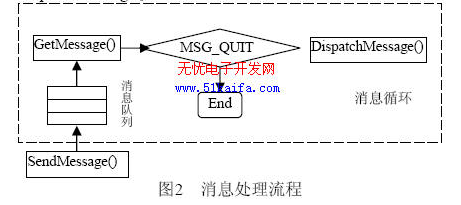
在Linux环境下,我们可以结合分度头应用和数据整合设计方案,实现更高效、更灵活的数据处理流程,具体实践方法包括:
1、利用分度头应用将大型数据集分割成较小的片段,降低处理难度和系统负载。
2、采用合适的数据整合方案,将不同来源、格式和结构的数据进行统一整合和处理。
3、结合Linux环境下的各种开源工具和框架,实现数据处理流程的自动化和智能化。
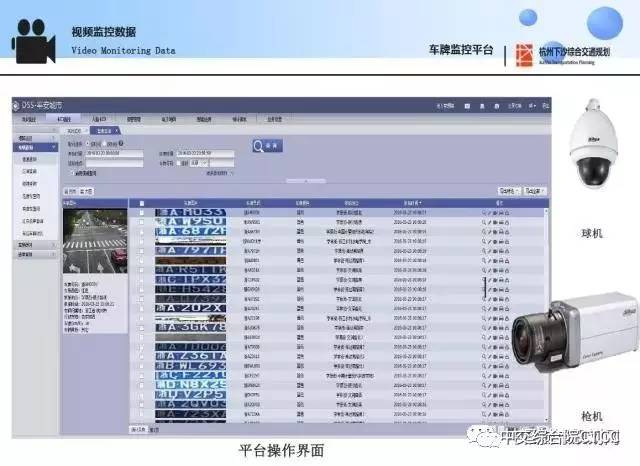
4、不断优化数据处理流程,提高数据处理效率和质量,满足实际需求。
案例分析
为了更好地说明分度头应用与数据整合设计方案在Linux环境下的实践,我们可以结合具体的案例进行分析,在大数据分析领域,我们可以利用分度头应用将海量数据进行分割和处理,然后通过数据整合方案将不同来源的数据进行统一整合和分析,从而得出更有价值的结论,在机器学习领域,我们可以利用分度头应用对训练数据进行分割和处理,提高模型的训练效率和准确性。
本文介绍了分度头应用与数据整合设计方案在Linux环境下的实践,通过结合具体的技术细节和实现方法,我们阐述了分度头应用的重要性以及数据整合设计方案的实施策略,随着大数据、云计算和人工智能等领域的不断发展,分度头应用与数据整合技术将面临更多的挑战和机遇,我们将继续探索更先进、更高效的数据处理技术和方法,为相关领域的发展做出更大的贡献。